
Why the Most Advanced AI Still Can’t Think in Space
Why OpenAI’s “Month-of-Compute AGI” Can’t Follow a Crayon Line—and What That Tells Us About the Future of Reasoning

OpenAI just released o4. It’s the newest model in their flagship line—multimodal, fast, and allegedly capable of doing things like discovering new drugs if you let it “think” for a month.
I’m not mocking that. I believe it might be true.
But it still fails a diagram that any three-year-old could solve with a crayon and a moment of attention.
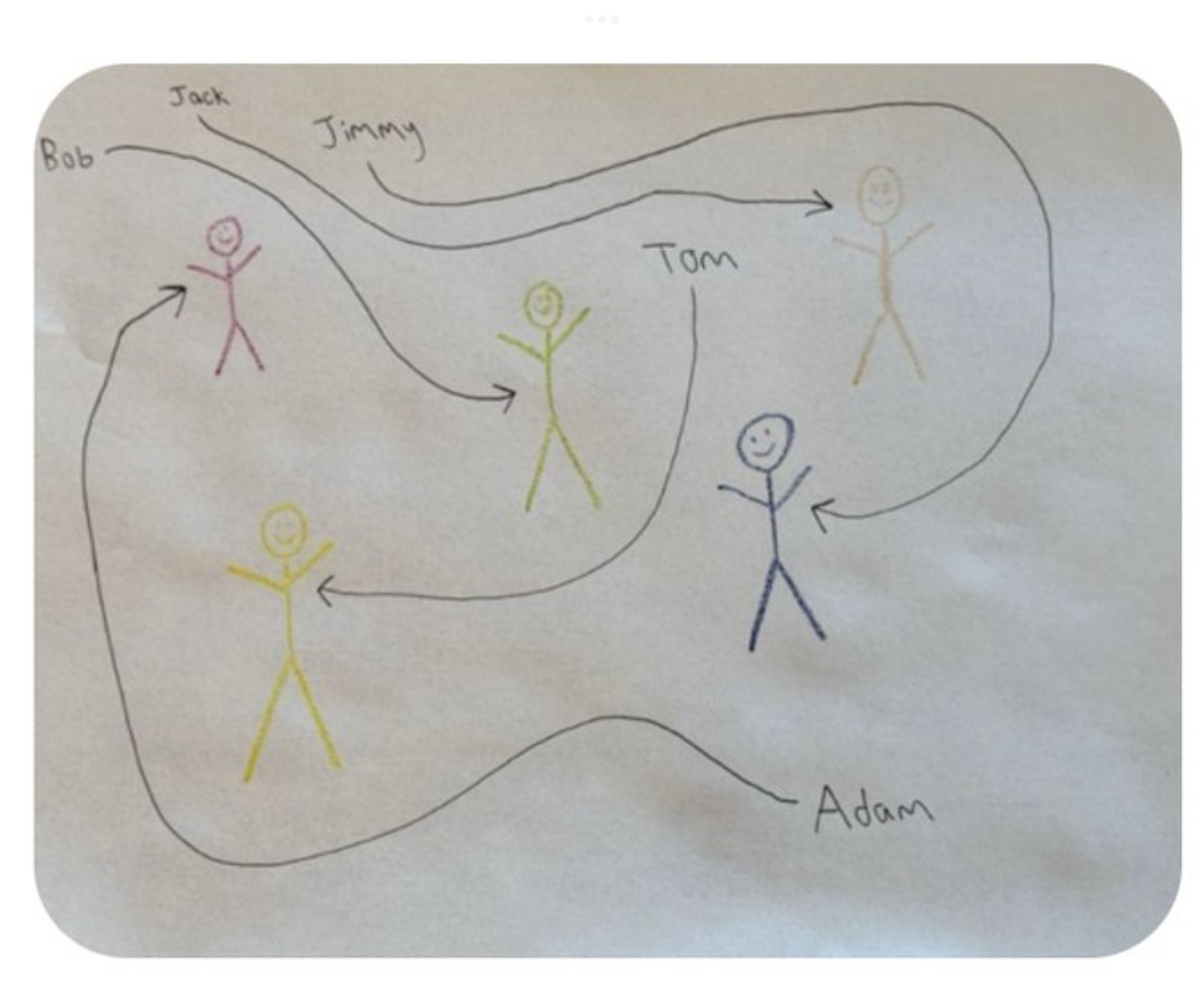
1. The Diagram That Breaks the Illusion
A user on Twitter tested o4-mini-high—a smaller version of o4 (“mini” meaning fewer parameters, think of it as a lower IQ model) but configured to think for a long time (“high” meaning extended inference). It’s designed to do more reasoning per token, slowly.
This isn’t some gimmick. OpenAI says the top-tier version of this model might generate drug discoveries if allowed to think for a full month.
So they gave it a simple prompt: match five names to five stick figures using curved arrows in a basic diagram.
It failed.
I then tried the same task with GPT-4o, OpenAI’s best publicly available multimodal model (not a chain-of-thought reasoner like o4, but my daily tool and I can often reproduce the same results manually). I prompted it step-by-step. I slowed it down. I used every tool I know.
It failed too.
2. Why This Isn’t a “Gotcha”
This might sound like one of those “LLM fail” dunk posts. But it’s not. I actually agree with people like Tyler Cowen and Alexey Guzey—o4 is astonishing. It’s probably the closest thing to “AGI” we’ve seen in the open.
But that’s exactly why this failure matters.
If the model that might one day discover new molecules can’t solve a toddler’s visual reasoning task, that’s not a bug. That’s an architectural boundary.
3. I Tried Everything: The Limits of NLP Tricks
Let me be clear: I didn’t just toss the diagram at GPT-4o and ask “who’s red?” I used the full prompt engineering toolbox:
Step-by-step reasoning
Chain-of-thought prompts
Grid overlays
Pseudocode-style logic
Visual segmentation
Symbolic memory scaffolding
Still wrong. Every time.
Because this isn’t a language task. It’s a spatial-symbolic task. The kind of thing humans solve by simulating space, tracing paths, and binding symbols across steps. LLMs just don’t think that way.
4. How Humans Solve This Instantly
This is what a human (even a young child) does when they look at the diagram:
Recognize the name as a symbolic anchor
Mentally trace the curved arrow from that name
Land on the corresponding stick figure
Read the figure’s color
Bind that color to the name
Repeat five times without breaking a sweat
This isn’t “training.” It’s intuitive, embodied, simulation-based reasoning.
LLMs don’t do any of this. They don’t simulate movement. They don’t keep symbolic bindings stable across shifts. They just guess the next likely token.
5. How Vision Actually Works in These Models
Here’s the crux: when transformers “see,” they don’t see like we do.
Humans perceive dynamically, simulate paths, integrate across time, and revise based on uncertainty.
Transformers analyze static image patches, attend to local features, and make token predictions.
So when o4 looks at a curved arrow, it doesn’t trace it. It doesn’t even understand “curved” as continuous. It chunks the arrow into local patches and makes statistical guesses about which tokens go together.
That’s why it fails—even on something so simple.
6. What This Means for the “Maybe AGI” Debate
I still believe o4 might one day help discover new drugs. But we need to be honest about what it can’t do.
Until models can:
Represent space
Simulate continuity
Maintain symbolic memory
Acknowledge and manage uncertainty
…they will keep hitting the same wall.
And the worst part? When they hit that wall, they don’t say “I don’t know.” They hallucinate. Confidently.
That’s fine for writing a blog post. It’s dangerous for decision-making systems.
7. This Isn’t About Crayons
This task isn’t a toy. It reveals a foundational gap between how humans reason and how transformers operate.
No amount of token prediction will give you spatial simulation. No amount of prompting will bind symbols across visual curves unless the architecture can support it.
Until we close that gap, even the smartest models on earth won’t be able to follow a crayon line.
More soon,
Trey
Domesticating Silicon